A guide to Kubernetes Operators
What is an operator
An operator is an application that extends Kubernetes with new custom resources. They allow you to add new resource types (also referred to as kind) to your Kubernetes cluster. The operator is then responsible for watching changes to these custom resources and change the state of your infrastructure accordingly.
For example, the etcd-operator extends your Kubernetes cluster with the ETCD resource kind, allowing users of your cluster to spin up ETCD databases without having to worry about all the details, such as provisioning volumes for the ETCD cluster.
And it doesn’t stop at just the creation of the ETCD database! The ETCD operator provides advanced features such as failover, backups and rolling upgrades! Normally, a cluster admin would get involved in order to handle a rolling upgrade of an ETCD cluster. Now we can automate these complicated manual tasks! That really shows the power of the operator pattern: it goes far beyond just resource provisioning.
Red Hat defines several operator capability levels on the OperatorHub:
- Basic Install: These operators are capable of automated application provisioning and provide the ability for managing the configuration of the application
- Seamless Upgrades: Upgrades of patch and minor versions should be supported by the operator
- Full Lifecycle: The operator should handle both the storage lifecycle of an application (which includes backups and automated failure recovery) as well as the application lifecycle.
- Deep Insights: Metrics, logs, alerts and workload analysis should all be handled by the operator.
- Auto Pilot: The operator is fully responsible for your application. It should automatically scale your application, tune the configuration and detect abnormal behaviour.
Human operators often understand everything about the applications they maintain. They know how to perform upgrades of the application, what to do when the CPU is overloaded and how to failover to another instance. But these steps often also require manual intervention of the human operator. Operators really aim to capture the know-how of human operators in code. Operators provide you with a means to scale your applications without having to worry your overloading the ops team.
How does an operator work
Operators utilise the control loop pattern. They watch the Kubernetes API for changes in the desired state, often expressed as custom resources although operators can also extend existing resources such as the Service or Job kind. The operator is then responsible for reconciling the desired state with the current state. The diagram below explains this relation schematically.
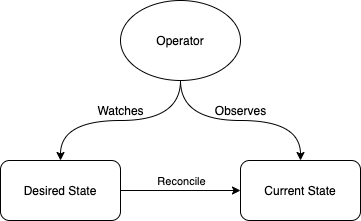
Control loops originate from industrial control systems. You can imagine a chemical engineering plant, where a control loop is responsible for maintaining the desired state of a reactor. The control loop will watch the reactor for changes in temperature and pressure, and will make adjustments to the reactor to ensure the current state matches the desired state. Both unexpected changes in the environment (e.g. a reactor overheating) as well as changes by the chemical engineers maintaining the reactor (e.g. increasing the heat in the reactor for the second phase of a chemical reaction) trigger the control loop to reconcile current state with desired state.
Often when developing operators you will want to add a new resource to your Kubernetes cluster, such as the kind ETCD. This kind services as an abstraction between the underlying infrastructure and the end user. Kubernetes allows you to easily and dynamically add new custom resources using custom resource definitions (CRDs). These custom resources extends Kubernetes with a new resource definition and adds a new endpoint to the Kubernetes API. Kubernetes will implement the common restful operation for this new resource, such as GET, POST, PUT, DELETE. kubectl leverages the Kubernetes API, meaning kubectl get my-custom-resource will fetch a list of the my-custom-resource kind. Kubernetes will store this new information in the ETCD database backing the Kubernetes cluster.
On their own, these custom resources are simple a way of storing data in Kubernetes. However, combined with a custom operator, custom resources provide a powerful declarative API for managing your infrastructure. Custom resources express the desired state and the operator will continuously update your infrastructure to reflect this desired state.
An interesting side note is the fact that a lot of build-in Kubernetes resources are now implemented via custom resources. This provides a lot of modularity to Kubernetes, as a cluster administrator can decide to remove certain build-in kinds by removing the CRD and associated operator. Kubernetes will dynamically deregister the resource from it’s API.
CRDs
CRDs (or CustomResourceDefinitions) are a method of extending the Kubernetes API with new custom resources. A CRD is defined by a name, group, schema and scope. See the code snippet below for an example:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: cronjobs.blokje5.dev
spec:
group: blokje5.dev
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
schedule:
type: string
image:
type: string
scope: Namespaced
names:
plural: cronjobs
singular: cronjob
kind: CronJob
shortNames:
- cjThe name of a resource is defined by the plural of the kind (e.g. cronjobs) and the group name. The group name is just a mechanism to prevent name conflicts within a cluster. The group is ideally a domain owned by you, to ensure your new kind is globally unique.
The schema is defined for one or more versions of your kind. This allows you to evolve your schema over time. Initially you might start out with a v1alpha1 version to indicate that your API is still unstable, but over time you might release an actual v1 version. The schema is defined as an OpenAPI 3.0 spec. This allows you to define what fields are defined for your custom resource and of what type these fields are. It is also possible to define (basic) validations on your API here, such as regex pattern checks.
The scope defines whether your custom resource is Namespace or Cluster scoped. A Namespace scoped operator operates within the boundaries of a namespace. An example of a namespace scoped operator is the Strimzi Kafka Operator, which will only create Kafka clusters in a namespace defined on installation of the operator. A Cluster scoped resource watches all namespaces. Cert-manager is an example of a Cluster scoped operator as it will provision certificates in all namespaces.
Once a CRD is submitted to the CRD API in Kubernetes, Kubernetes will add the new resource to it’s own API server. This automatically ensures that users can use kubectl to work with your new custom resource. It will ensure that your resource is stored in the ETCD database backing Kubernetes. No additional API servers are needed at all!
Writing an operator
Now that we have seen how an operator works and what components are needed we can dive into how to write your own operators. As mentioned above, there are two main components to writing an operator: defining a new kind and writing a controller that watches this new kind and changes the state of the cluster based on the desired state. Kubernetes luckily already provides an easy mechanism for defining new kinds through CRDs, even though writing a large OpenAPI spec can be cumbersome (we’ll dive into ways to simplify this latter). So in this section we’ll focus on writing the controller.
A controller does nothing more then interact with the Kubernetes API (and potentially other APIs). The controller has to fetch the latest desired state of the new kind from the Kubernetes API, and the controller then interacts with the Kubernetes API to reconcile the current state with the desired state. For example, the CronJob controller watches the Kubernetes API for new CronJobs, and then based on the job definition and cron schedule it will ask the Kubernetes API to create a container running at the scheduled time.
The Kubernetes API has a RESTful interface. Creating resources is a matter of POSTing to the respective resource endpoint. Checking the latest definition of a resource is a matter of calling the respective GET endpoint. It even supports a helpful change notification mechanism using watches. All the tools are there for writing a controller.
While it is definitely possible to directly interact with the Kubernetes API, there are also a lot of API client libraries that handle a lot of the details of interacting with the Kubernetes API, such as authentication and handling error responses. For example, when interacting with the Kubernetes API in golang, you can use the client-go library.
The client-go library also provides useful abstractions for creating operators. It provides the ListWatcher to first list a set of resources from the Kubernetes API and then watch for changes. The Informer then uses the change events provided by the ListWatcher to trigger one or more ResourceEventHandlers. ResourceEventHandlers provide hooks for changes to a resource, such as OnAdd and OnDelete. This can be used to implement the control loop described above: The ResourceEventHandlers ensure the current state is reconciled with the desired state. There is a great blog post from Bitnami that has a more in depth explanation on each of these abstractions.
Operator Frameworks
However, manually interacting with the Kubernetes API, even when utilising the great client libraries, leads to a lot of boiler plate code. You have to initialise the ListWatchers and Informers correctly and configure them to watch the right resources. You have to create a CRD, which can take hundreds or even thousands of lines of yaml to write. You have to figure out what RBAC permissions your operator needs in order to connect to the Kubernetes API. And then we haven’t even started talking about logging, monitoring & testing.
Luckily there are several frameworks that reduce the boilerplate code for your operator and allow you to focus on writing the reconciliation loop. There are frameworks for Golang, Java and Python. There are even frameworks that allow you to write operators using Helm or Ansible. The following list shows a few of the most used operator frameworks:
- Kubebuilder: A golang based framework for writing Kubernetes Operators. It utilises the controller-runtime library under the hood.
- Operator SDK: Also a golang based framework that has a lot of similarities with Kubebuilder. However, it also supports Ansible and Helm based operators.
- Kudo: A framework that allows you to build operators mostly using YAML.
- Kopf: If golang or yaml is not your style, you can also use python to write your operators.
Each of these frameworks have their own unique selling points. Depending on what you want to achieve you will choose a different framework. For example, Kudo is great for simple operators, but yaml is too limiting if you want to connect to external APIs or if you want to execute complex logic during reconciliation.
In the next blog post in the series I will explain how you can write an operator using the Kubebuilder framework.